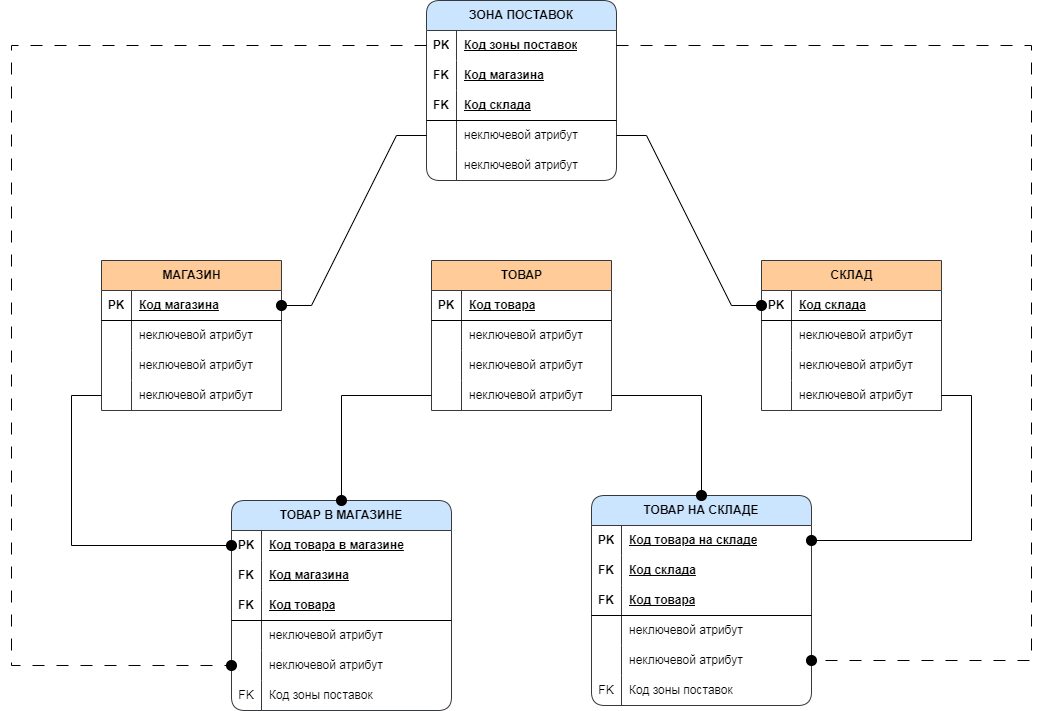
Да, две сущности, возникшие из одной родительской сущности, могут иметь схожие характеристики и одновременно отличаться в различных атрибутах или поведении. Это может быть результатом наследования и специализации в объектно-ориентированном программировании или в результате дизайна базы данных. В контексте базы данных это явление может быть описано с помощью парадигмы наследования таблиц.
В базах данных могут возникнуть различные проблемы при работе с сущностями-потомками. Относительно нормализации и логической структуры базы данных, рассмотрим возможные проблемы на примере таблиц "Товар в магазине" и "Товар на складе":
1. Проблемы дублирования данных:
Если "Товар в магазине" и "Товар на складе" имеют общие данные (какие-то характеристики товара), которые дублируются в обеих таблицах, это может привести к избыточности, затруднять поддержку данных и увеличивать риск появления ошибок.
2. Нарушение целостности данных:
Если обновление информации о товаре происходит отдельно в каждой из таблиц, существует риск несогласованности данных. Например, если изменения цены товара вносятся только в таблицу "Товар в магазине", данные в таблице "Товар на складе" окажутся неактуальными.
3. Сложность обновления структуры:
Если потребуется добавить новый атрибут к общим характеристикам товара, придется внести изменения в обе таблицы, что может быть трудоемко и подвержено ошибкам.
4. Проблемы запросов и производительности:
Запросы, которые требуют объединения данных из этих двух таблиц, могут быть более сложными и менее эффективными по сравнению с ситуацией, когда общие данные хранятся в отдельной родительской таблице.
Решениям данных проблем могут служить:
- Реализация наследования таблиц: создание общей родительской таблицы для хранения общих характеристик товаров, от которой будут наследоваться "Товар в магазине" и "Товар на складе".
- Использование триггеров для синхронизации изменений в связанных таблицах, однако это может внести сложность в логику базы данных.
- Предпочтение нормализованной схемы, в которой общие атрибуты хранятся только в одном месте, чтобы избежать дублирования данных.
Следует учитывать, что оранжевые и синие таблицы означают некий условный цветовой код, который, вероятно, обозначает различия между сущностями или группами таблиц в вашем контексте. Подход к решению может варьироваться в зависимости от обстоятельств и конкретных требований приложения или доменной модели.