### Объединение строк в Pandas, сгруппированные по определенному столбцу:
Чтобы объединить строки в DataFrame библиотеки Pandas, сгруппированные по определенному столбцу, вы можете использовать метод `groupby` вместе с функцией `agg`, которая позволяет применять агрегирующие функции к группам. Например, чтобы объединить текстовые данные, можно использовать функцию `join`:
```python
import pandas as pd
# Создаем пример DataFrame
df = pd.DataFrame({
'Group': ['A', 'A', 'B', 'B', 'A'],
'Text': ['Hello', 'World', 'Foo', 'Bar', 'Baz']
})
# Группируем по столбцу 'Group' и объединяем текст
grouped_df = df.groupby('Group')['Text'].agg(' '.join).reset_index()
print(grouped_df)
```
В этом примере строки с одинаковыми значениями в столбце 'Group' будут объединены, и текстовые данные из столбца 'Text' будут собраны в одну строку, разделенную пробелом.
### Объединение строк в файле xlsx:
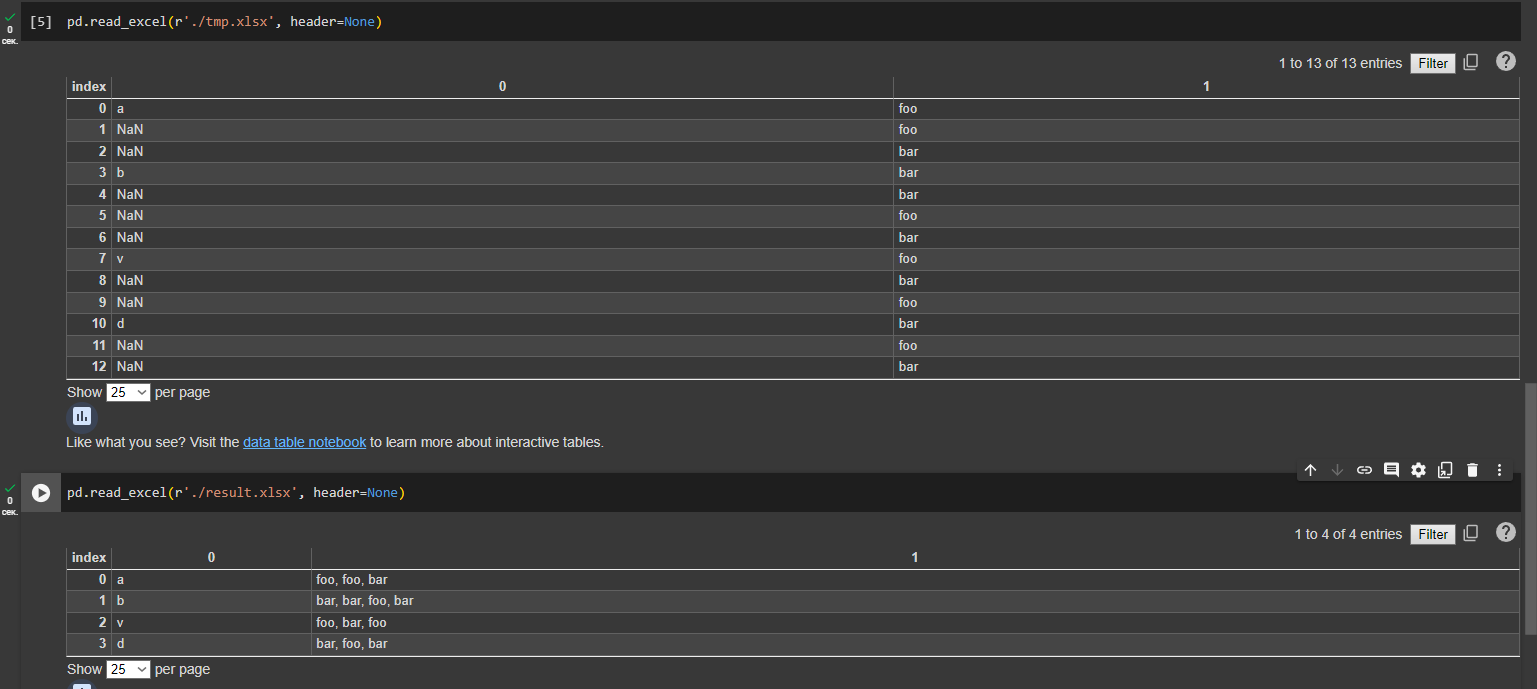
Объединение строк в Excel файле может быть выполнено с использованием библиотеки Pandas для чтения данных и последующей их обработки. Предположим, что вы хотите объединить строки до следующего появления непустого значения в первом столбце:
1. Прочитайте данные из файла Excel.
2. Используйте кумулятивную сумму для определения групп, где каждый непустой элемент в первом столбце начинает новую группу.
3. Группируйте по созданному идентификатору группы и объедините соответствующие данные.
4. Сохраните результат обратно в файл Excel.
Пример кода:
```python
import pandas as pd
import numpy as np
# Читаем файл Excel
xlsx_file = 'path_to_your_file.xlsx'
df = pd.read_excel(xlsx_file)
# Определяем новые группы на основе того, где первый столбец не пустой
df['Group'] = df.iloc[:, 0].notna().cumsum()
# Группируем по новому идентификатору группы и объединяем строки
grouped_df = df.groupby('Group').agg(lambda x: ' '.join(x.dropna()))
# Удаляем колонку Group и сохраняем результаты в новый файл Excel
grouped_df.drop('Group', axis=1, inplace=True)
grouped_df.to_excel('path_to_your_output_file.xlsx', index=False)
```
Этот код создаст новый файл Excel с объединенными данными. Обратите внимание, что, в зависимости от структуры исходных данных, вам может потребоваться адаптировать код, чтобы он корректно работал с вашим набором данных.