Как наилучшим образом структурировать и хранить большие объемы данных, чтобы обеспечить максимальную скорость доступа к этим данным для генерации отчетов?
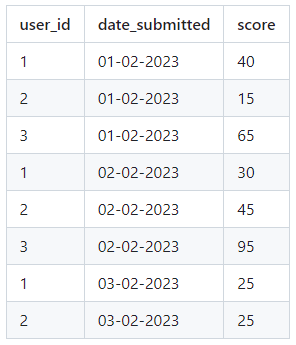
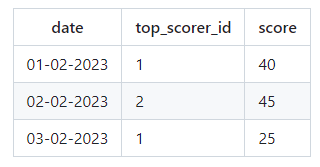
Как лучше организовать хранение данных и эффективно получать их для отчетов, чтобы определить пользователей с наивысшим баллом в заданном диапазоне дат, учитывая условие, что пользователь должен подавать заявку каждый день в течение этого периода? К примеру, для дат start_date: 01-02-2023 и end_date: 03-02-2023, пользователь с ID 1 был лучшим 1 февраля, пользователь с ID 2 был лучшим 2 февраля, а 3 февраля пользователи с ID 1 и 2 набрали равное количество баллов, и мы случайным образом выбрали пользователя с ID 1 для отчета.
- 10 октября 2023 г. 8:47
Для эффективной структуризации и хранения больших объемов данных, можно использовать базу данных, такую как PostgreSQL или MongoDB. При организации хранения данных в базе данных, можно использовать следующую структуру: - Создать таблицу "Users" с полями "ID", "Name" и другими необходимыми атрибутами пользователей. - Создать таблицу "Scores" с полями "UserID", "Date" и "Score", чтобы хранить данные о результатах пользователей на каждую дату. В этой таблице каждая строка будет представлять отдельный результирующий счет пользователя. Для получения данных о пользователях с наивысшим баллом в заданном диапазоне дат, можно выполнить следующий SQL-запрос: SELECT UserID FROM Scores WHERE Date >= start_date AND Date <= end_date GROUP BY UserID HAVING COUNT(DISTINCT Date) = (end_date - start_date) + 1 ORDER BY SUM(Score) DESC LIMIT 1; Этот запрос выберет пользователя с наивысшим суммарным баллом в заданном диапазоне дат, который также отправил заявку каждый день в течение этого периода. Если есть несколько пользователей с одинаковым суммарным баллом, то для выбора одного можно добавить дополнительное условие или использовать случайную функцию для выбора пользователя среди них. Чтобы обеспечить максимальную скорость доступа к данным для генерации отчетов, можно применить следующие подходы: - Индексирование: Создать индексы на поля "Date" в таблице "Scores", чтобы ускорить выполнение запросов, основанных на фильтрации дат. - Кеширование: Использовать систему кеширования, чтобы временно хранить результаты запросов и избегать повторного выполнения дорогостоящих операций запросов при повторных запросах в отчетах. - Параллельное выполнение запросов: Распараллеливать выполнение нескольких запросов для ускорения обработки данных. - Предварительное вычисление: Периодически (например, ежедневно) вычислять и сохранять промежуточные результаты, такие как суммарные баллы пользователей для каждой даты, чтобы ускорить выпуск отчетов. Реализация этих подходов может немного различаться в зависимости от используемой базы данных и инструментов разработки.
Структура таблицы хорошая, но я рекомендую добавить индекс на поле date_submitted и индекс на поле score. Это значительно улучшит производительность вашей базы данных.
Запрос для получения рейтинга на каждый день для всех пользователей может выглядеть следующим образом:
```
WITH date_list AS (
-- Любым способом получаете непрерывный список дат интересуемого диапазона
)
SELECT A.date, u.user_id, COALESCE(A.max_score, 0) AS max_score
FROM (
SELECT dl.date, u.user_id, tb_max_score.max_score,
RANK() OVER (PARTITION BY dl.date ORDER BY RANDOM()) AS rnk
FROM (
SELECT us.date_submitted, MAX(us.score) AS max_score
FROM user_score us
) tb_max_score -- выясняем максимальные баллы
LEFT JOIN date_list dl ON dl.date = tb_max_score.date_submitted
LEFT JOIN user_score us ON dl.date = us.date_submitted -- выясняем, у кого максимальные баллы
AND us.score = tb_max_score.max_score
) A
CROSS JOIN user u ON u.user_id = A.user_id -- прицепляем тех, кто возможно не участвует в рейтинге
WHERE A.rnk = 1
```
Теперь о двух сильных путях оптимизации в базе данных:
1) Минимизация IOps. Для этого рекомендуется использовать разделение таблицы на партиции по полю date. Экспериментально определите оптимальный размер партиции (например, 1 неделя). Таким образом, запросы, работающие в заданном диапазоне дат, будут обращаться только к одной или двум партициям, что значительно уменьшает число дисковых чтений.
2) Материализация ответов. Для данных, которые не будут изменяться, можно построить материализованное представление (Materialized View) или OLAP-кубы, в которых будут заранее рассчитаны необходимые данные. Таким образом, можно избежать повторного выполнения сложных вычислений. Примером такого материализованного представления может быть таблица с результатами:
```
start_date | end_date | result
01-02-2023 | 03-02-2023 | { "1":"65", "2":"45" }
```
Для оптимального использования такого представления можно создать индекс по двум датам.