Как выполнить расчеты для нескольких групп в SQL?
Как можно улучшить алгоритм для создания таблицы, отображающей изменения статуса тикетов, чтобы избежать повторной группировки данных?
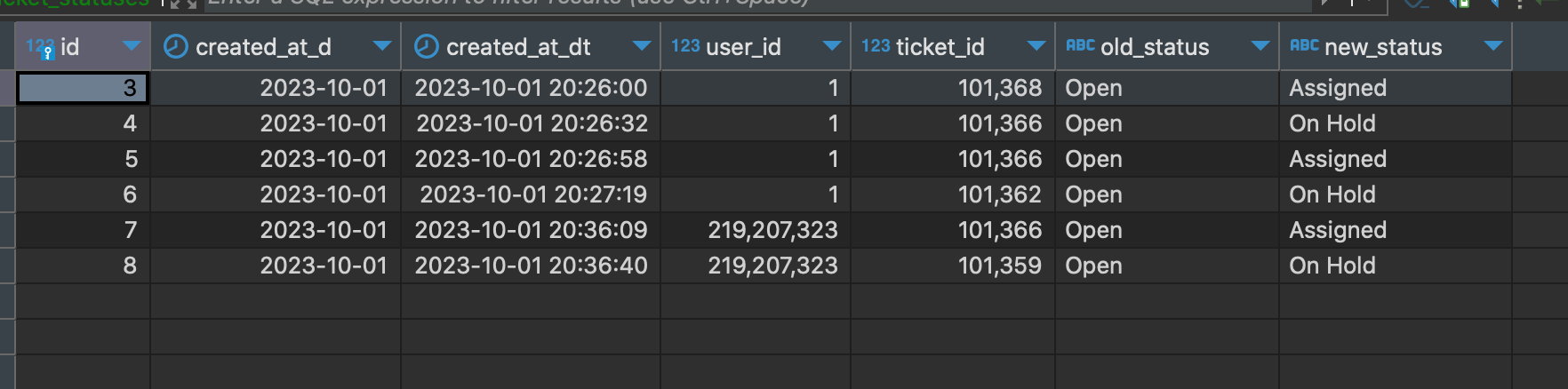

- 9 октября 2023 г. 23:07
Чтобы выполнить расчеты для нескольких групп в SQL, вы можете использовать операторы GROUP BY и функции агрегирования, такие как SUM, AVG, COUNT и т. д. Предположим, у вас есть таблица "tickets" с колонками "group_id" и "amount". Вы можете выполнить расчеты для каждой группы, сгруппировав данные по "group_id" и затем применив функцию агрегирования к колонке "amount". Пример: ``` SELECT group_id, SUM(amount) AS total_amount FROM tickets GROUP BY group_id; ``` Для улучшения алгоритма создания таблицы, отображающей изменения статуса тикетов, и избежания повторной группировки данных, можно использовать оконные функции. Оконные функции позволяют работать с окнами данных, которые представляют подмножества данных внутри группы. Вы можете использовать функции, такие как LAG или LEAD, чтобы получить значения предыдущей или следующей строки в рамках каждой группы. Пример: ``` SELECT ticket_id, status, LAG(status) OVER (PARTITION BY group_id ORDER BY timestamp) AS previous_status FROM tickets; ``` Этот запрос представляет каждый тикет с его текущим статусом и предыдущим статусом в рамках каждой группы, без необходимости повторной группировки данных.
select t.user_id,
count(*) as общее количество звонков,
count(case when t.old_status = 'Open' then 1 end) as количество открытых заявок,
count(case when t.new_status = 'Assigned' then 1 end) as количество назначенных заявок
....
from log_ticket_statuses t
group by t.user_id
PS: Рекомендуется создать отдельный справочник для статусов, чтобы не использовать их в виде строк.
PPS: Почему не использовать связанные строки id_next для отслеживания истории состояний заявок? Можно добавить неограниченное количество переходов статусов для одного пользователя, а запросы для определения завершенных треков и текущих статусов пользователей удобно составлять по маркеру id_next.
history_id, ticket_id, user_id, status_id, next_history_id
1, 1, 1, 1, 2
2, 1, 1, 2, null
3, 1, 2, 1, null
4, 2, 2, 1, 5
5, 2, 2, 2, null