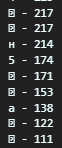
Для извлечения данных из PDF-файла в Python можно использовать библиотеку PyPDF2. Вот пример использования:
```python
import PyPDF2
def extract_data_from_pdf(file_path, output_file):
pdf_file = open(file_path, 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
page_count = pdf_reader.numPages
data = {}
for i in range(page_count):
page = pdf_reader.getPage(i)
content = page.extractText()
for char in content:
if char in data:
data[char] += 1
else:
data[char] = 1
pdf_file.close()
output = open(output_file, 'w')
for char, count in data.items():
output.write(f"{char}: {count}\n")
output.close()
# Пример использования
extract_data_from_pdf('example.pdf', 'output.txt')
```
Этот код открывает PDF-файл 'example.pdf', читает каждую страницу и подсчитывает количество каждого символа на странице. Затем результат записывается в текстовый файл 'output.txt'.
Помните, что извлечение текста из PDF-файла может быть не всегда точным из-за различных форматирований и шрифтов в PDF.