Как можно исправить ошибки в коде на Python?
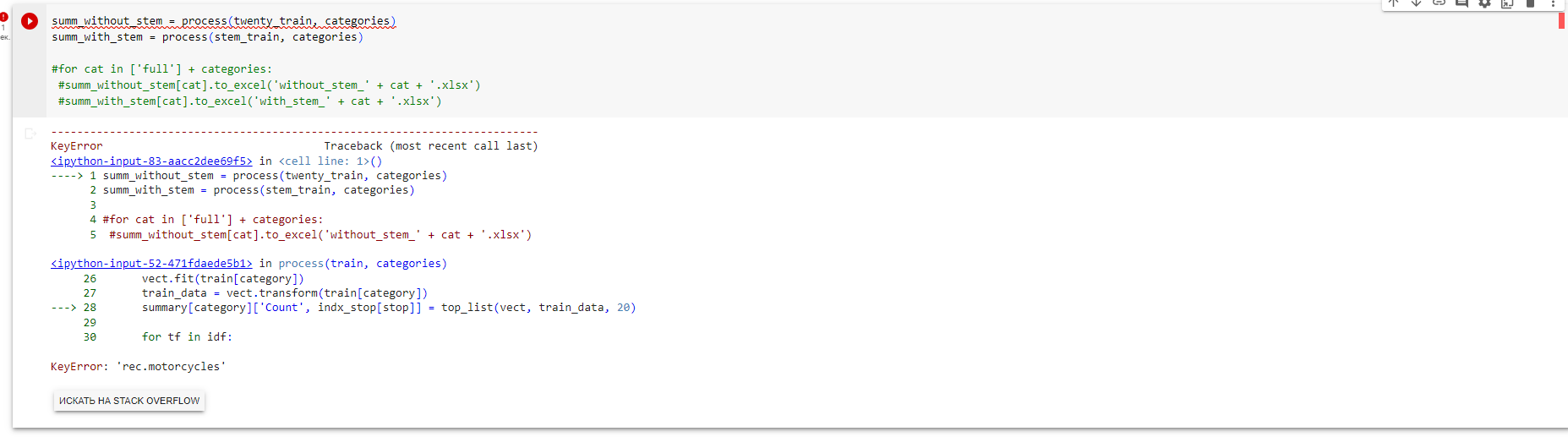
Какие шаги или изменения нужно сделать для исправления ошибки, показанной на скриншоте, при выполнении данного кода?
- 14 сентября 2023 г. 6:46
Для исправления ошибки на скриншоте, следует выполнить следующие шаги или изменения: 1. Проанализировать ошибку, чтобы понять причину ее возникновения. 2. Изучить контекст, в котором происходит ошибка, чтобы понять, какие переменные или функции могут быть связаны с проблемой. 3. Проверить правильность написания кода, включая синтаксические конструкции, и убедиться, что все переменные и функции объявлены и определены корректно. 4. Проверить правильность использования операторов, функций и методов для правильной работы кода. 5. Устранить синтаксическую ошибку, исправив опечатки, неправильное написание или уточнив синтаксическую конструкцию. 6. Проверить логику кода, чтобы убедиться, что все переменные и функции используются согласно своему предназначению и типу данных. 7. Запустить исправленный код и убедиться, что ошибка исправлена и код работает без проблем. 8. Проверить возможные пути улучшения и оптимизации кода для повышения его читаемости, производительности и надежности. Обратите внимание, что для конкретного кода и ошибки на скриншоте требуются более подробные сведения для определения и исправления ошибки.
1. Для создания словаря summary используйте массив cats в качестве ключей, а pandas фреймы в качестве значений. 2. Чтобы изменить подсет фрейма, используйте метод loc[index, column]. Учтите, что KeyError может возникнуть как при обращении к несуществующим ключам словаря, так и при обращении к несуществующим индексам фрейма. 3. Разделите код на функции, каждая из которых будет обрабатывать один фрейм и возвращать его. После проверки работы функции, соберите все фреймы в словарь. Декомпозиция кода и использование функций помогут вам контролировать процесс и задавать более точные вопросы. 4. CountVectorizer - это инструмент из библиотеки scikit-learn. Чтобы использовать его, ознакомьтесь с примерами в документации. Рассмотрите также применение Pipeline, который позволяет объединить последовательность трансформаций. На простом примере применения pandas все этапы обработки данных обычно не показывают, а используют Pipeline. В вашем коде пока не видно этапа работы с тестовым набором данных, но с помощью Pipeline трансформации будут применяться к тестовым данным автоматически, если все ваши трансформации будут объединены в Pipeline.