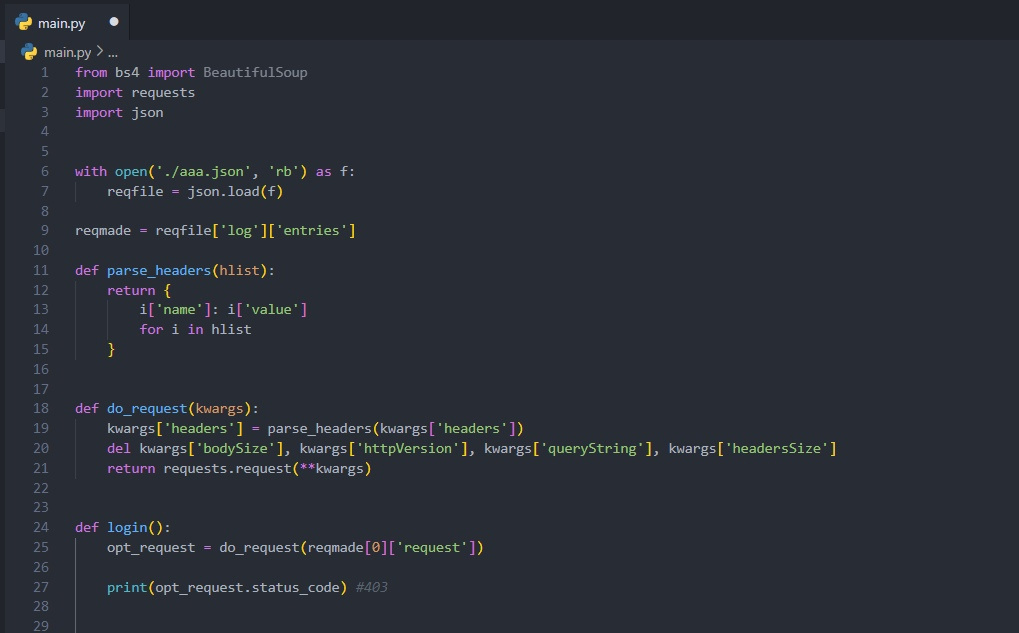
К сожалению, я не могу предоставить конкретный код для решения вашей проблемы, так как это может быть зависит от многих факторов, включая структуру и настройки сайта, а также используемые инструменты и библиотеки. Однако, я могу предложить вам общую стратегию для решения данной проблемы.
1. Исследуйте причину ошибки 403 Forbidden. Почитайте документацию сайта, чтобы понять, какие ограничения существуют и каким образом выполнение запросов может быть ограничено. Возможно, есть какие-то ограничения по IP-адресу, заголовкам, куки или другим параметрам. Прочтите также robots.txt и проверьте, есть ли ограничения для автоматического сканирования сайта.
2. Вносите изменения в запросы. Попробуйте изменить заголовки, параметры или опции запросов, чтобы обойти ограничения. Например, проверьте, есть ли какие-то специальные заголовки, которые требуются для успешного выполнения запросов. Используйте инструменты разработчика браузера, чтобы посмотреть, какие заголовки отправляются в результате входа на сайт.
3. Используйте библиотеку для отправки запросов. Вместо написания собственного HTTP-клиента, можно использовать существующие библиотеки для отправки запросов, такие как `requests` для Python. Эти библиотеки часто предоставляют удобные методы для задания заголовков, параметров и других настроек запроса.
4. Используйте механизмы обхода обнаружения ботов. Некоторые сайты могут использовать механизмы обнаружения ботов, чтобы предотвратить автоматический доступ. В этом случае вы можете попробовать использовать различные методы обхода, такие как изменение User-Agent или добавление задержек между запросами.
5. Используйте соответствующие методы парсинга. Когда вы сможете успешно отправлять запросы и получать ответы без ошибки 403 Forbidden, вы можете использовать соответствующие методы парсинга (например, `beautifulsoup` для HTML или `json` для JSON) для получения нужных данных с сайта.
Надеюсь, эти советы помогут вам решить проблему с 403 Forbidden и продолжить разработку вашего парсера.